LLMs are getting better and better at coding. While their capabilities grow quickly, I find it still takes time for me to develop trust in the code that is generated.
At first, I didn't really trust any of the code changes made by LLMs, but, overtime, I feel that I've been able to develop an intuition for which changes I can mostly trust, which changes I should diligently review, and which changes I should just make myself.
However, the speed at which these models (and our methods of using them) are improving is so rapid that intuition needed can change very quickly. Code review, rather than code generation, often feels like the bottleneck.
It makes me think about how I can interface with code changes in a way that allows me to:
- trust the changes more, or
- more quickly recognize that a code change is not correct.
The current interface
The basic dif interface that we have been using to review human-generated code is still very similar to the interface we are using to review LLM-generated code. This interface feels a lot easier to use when humans were making code changes in (ideally) small, incremental steps. Especially if we are reviewing (or making) these changes, we are already probably baseline familiar with the codebase.
With LLM-generated code, I see the following differences:
- there are more larger scale changes, across files and broader sections of the codebase
- these changes happen a lot faster and have higher throughput
- these changes are possible with less familiarity with the codebase than before
We can currently only look at difs of lines of code in either as many files as we can fit onto our screen or into our heads. Beyond this mental context, the changes sometimes feel like a blackbox that I have to dive into to understand. Makes me think: how can I quickly scan for proof that I can trust the code changes?
 Lots of changes in one codebase.
Lots of changes in one codebase.
My mental process for reviewing code
Here are the steps I notice myself taking when reviewing any code:
- section out logical chunks of code
- find: which of these sections had changes?
- evaluate: based on what i asked the model to do, does it make sense for those sections to have changes? if no, ok cool something is incorrect.
- find: (a) what are the changes and (b) what are their effects on the output?
- evaluate: is that what I intended to do?
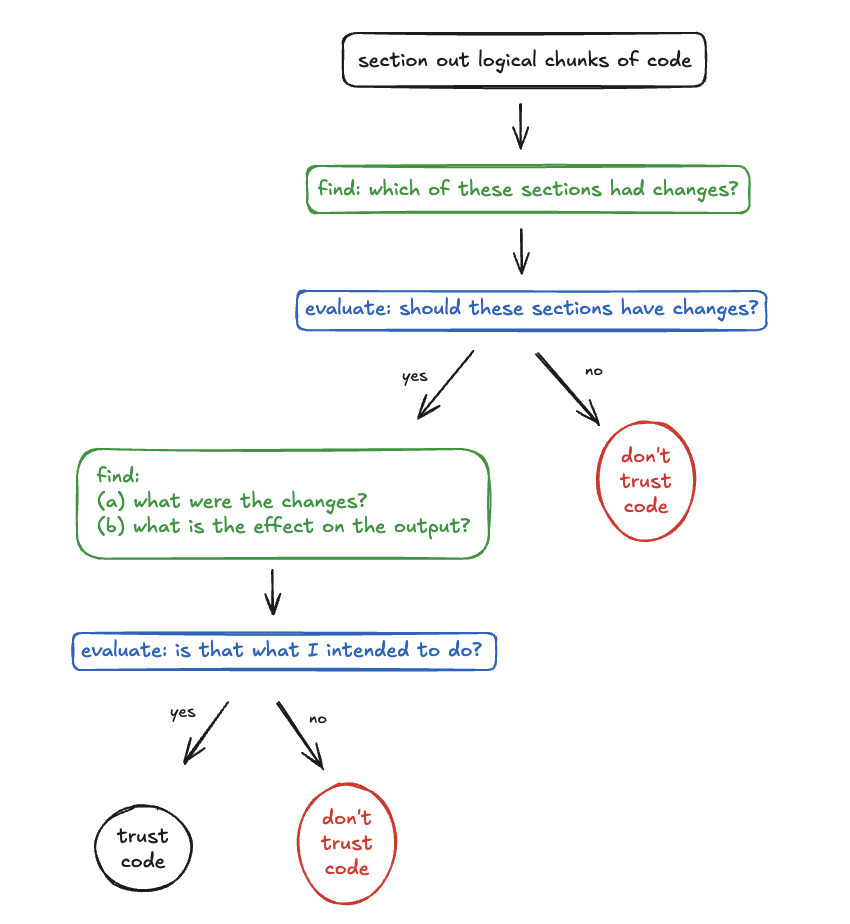
Which of these sections had changes + does it make sense for those sections to have changes?
This feels like something I can automate. Let's say we semantically label chunks of code.
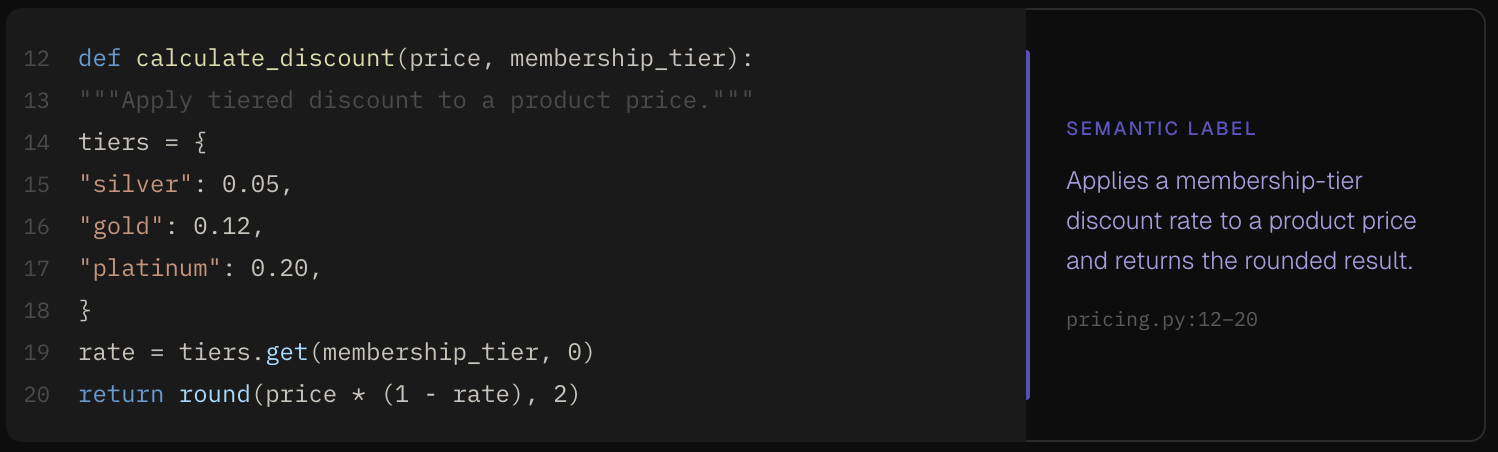
This would require the following steps:
- logically chunk the code
- use an llm to generate semantic labels for each chunk
Some challenges I see with this right away:
- How do we chunk the code? Are there different "correct" logical chunks? Does that affect labeling?
- If we chunk and then label chunks independently, how do we make sure that the labels make sense as a whole codebase?
If done perfectly, this would automate the "did I expect to make changes in these sections?" step.
How we actually interface with this data is what I find most interesting. Upon first glance, we just list something like:
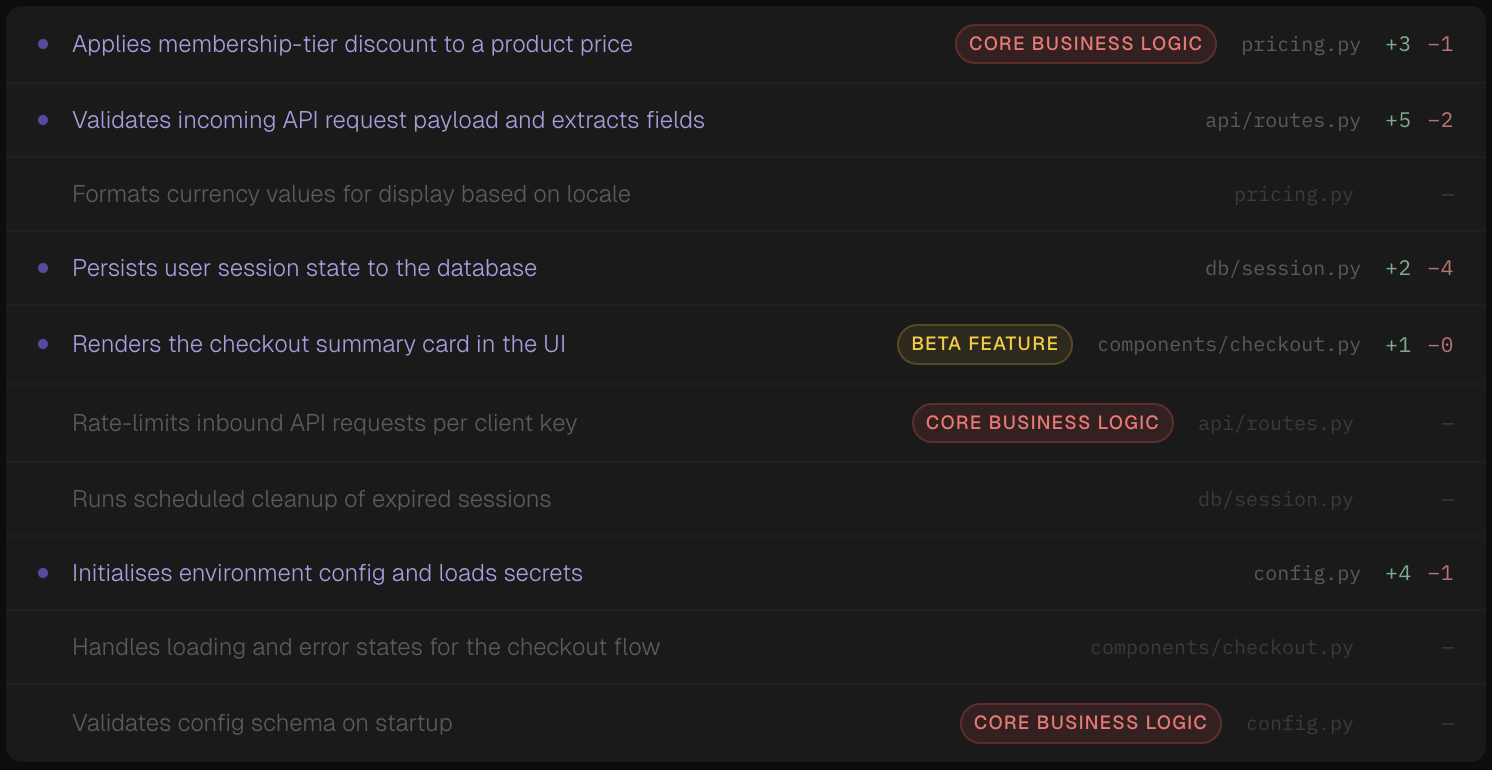
But -- I'd still doubt this. How do I know that the LLM is correct in saying that function X actually does X?
To remedy this, I envision something such as:
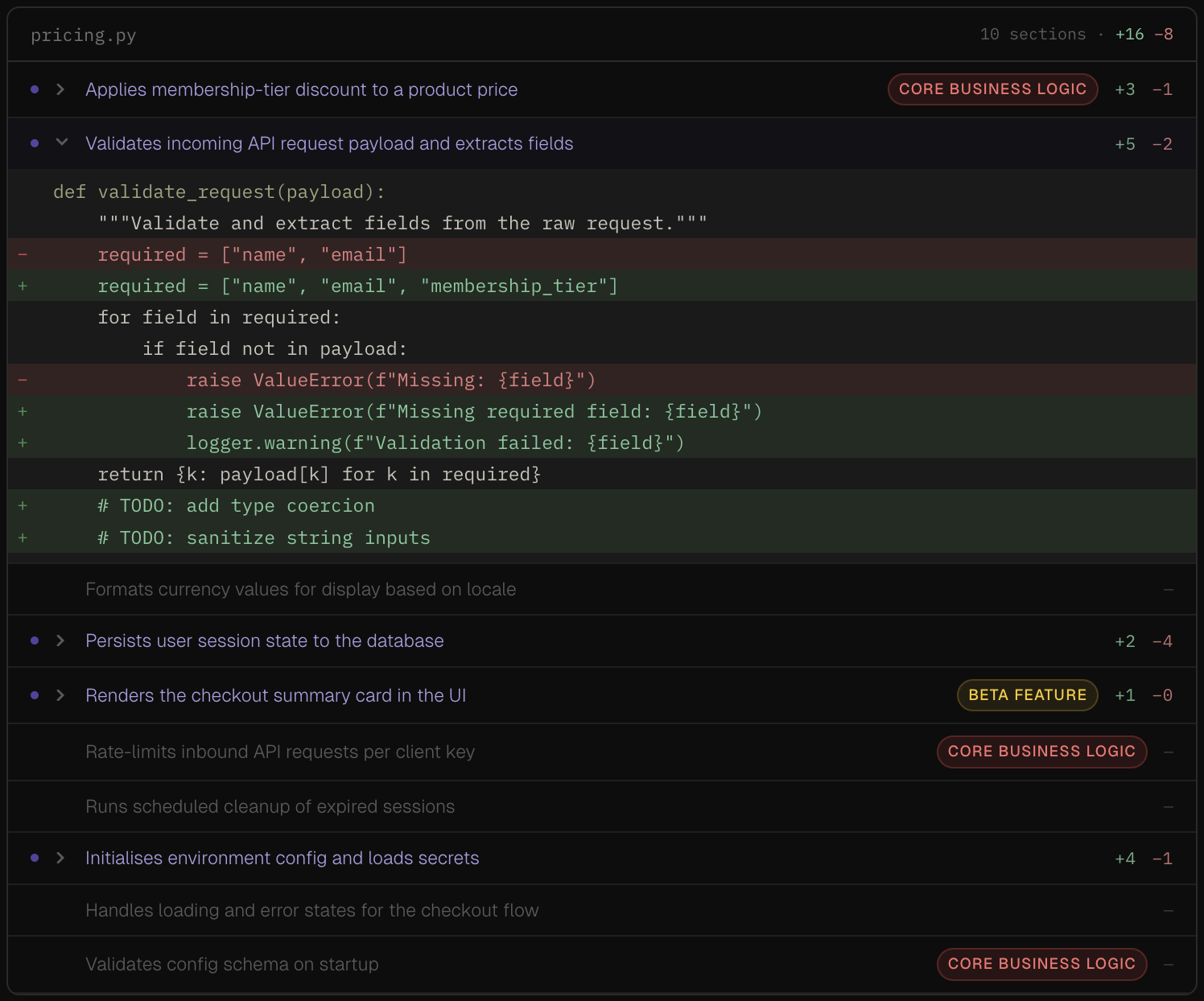
Here, we can click to un-collapse and verify the actual change in code.
I think this adds the following value:
- Understanding scope without reading all the code
- Pattern verification (did the LLM update all X sections?)
- Risk assessment (were the changes in the core business logic? or in a beta feature?)
- Selective deep-dive (can manually inspect only the high-risk or suspicious sections)
It could be argued that these values could be achieved through manual inspection -- but I feel this way of code reviewing might make the process more efficient. If I think about matching our speed of code review to the speed of code generation we can achieve with LLMs, this feels like something I'd want to try out.
Further thoughts + next interfaces
I see three places where we could start with having this interface:
- an external app
- a sidebar
- inline the files
Between 1 and 2 the only real difference (from a UX perspective) seems to be that we'd have to switch between two apps. So let's say we only have to pick between either (a) a sidebar or (b) inline.
My hypothesis is the benefit of an inline UI directly in the files that have changed is that it would be easier to put the changes into context of the rest of the files. The UI for this is tricky, as it involves re-rendering or overlaying the semantic labels somehow. However, the inline method still seems to have the limitation that we can only see as many files as we can open -- making it harder to connect changes across files.
For the sidebar UI, I envision a "map". We have a list of semantic areas that we can click to uncollapse and double click to open the related file and hop to that piece of code. We can zoom out and pan, seeing how various semantic segments across files are connected.
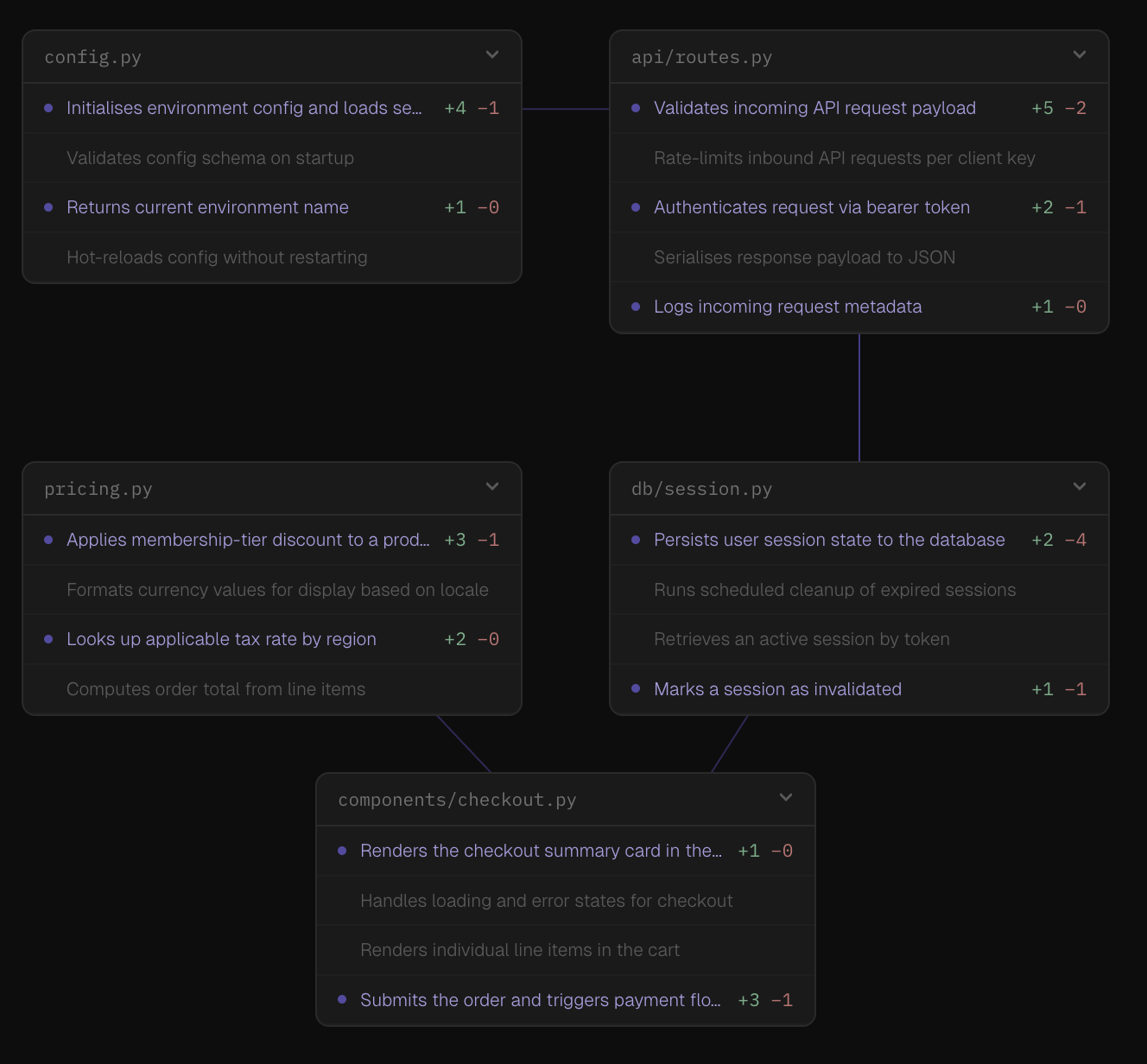
While writing this, this map concept feels dripping with different ways to connect code changes during review to add more context of a single change inside the entire app. Will explore that next.